


Alibaba’s Qwen2.5-Max Enters the Ring

Just days after DeepSeek’s AI breakthrough sent ripples through the tech world, Alibaba unveiled Qwen2.5-Max, a large-scale Mixture-of-Experts (MoE) model that is already being hailed as a game-changer in artificial intelligence.
“The burst of DeepSeek V3 has attracted attention from the whole AI community to large-scale MoE models. Concurrently, we have been building Qwen2.5-Max, a large MoE LLM pretrained on massive data and post-trained with curated SFT and RLHF recipes. It achieves competitive performance against the top-tier models, and outcompetes DeepSeek V3 in benchmarks like Arena Hard, LiveBench, LiveCodeBench, GPQA-Diamond. In the future, we not only continue the scaling in pretraining, but also invest in the scaling in RL. We hope that Qwen is able to explore the unknown in the near future!” — Alibaba Qwen
While much of the buzz around AI models tends to revolve around their commercial applications or competitive benchmarks, Qwen2.5-Max deserves attention for its technical ingenuity, its potential to reshape AI research, and its broader implications for how we think about machine intelligence. So, what exactly makes Qwen2.5-Max so significant? Let’s break it down.
Pushing the Boundaries of Model Intelligence
It’s no secret that scaling both data size and model size has historically led to significant improvements in AI performance. But Qwen2.5-Max takes this principle to new heights. Built on the Mixture-of-Experts (MoE) architecture, the model represents a paradigm shift in how AI systems are designed and deployed.
What is Mixture-of-Experts (MoE)?
For those unfamiliar with the term, MoE is a machine learning technique where multiple specialized models—referred to as “experts”—work together to solve different parts of a problem. Unlike traditional dense models that activate all parameters for every input, MoE uses a “sparse” approach, dynamically selecting only the most relevant experts for a given task.
This design not only enhances computational efficiency but also allows the model to tackle a wide variety of tasks with remarkable precision. In practical terms, this means Qwen2.5-Max can adapt seamlessly to diverse challenges, from generating human-like text to performing advanced reasoning and coding tasks. Its modular structure ensures that it doesn’t just perform well—it excels across domains.
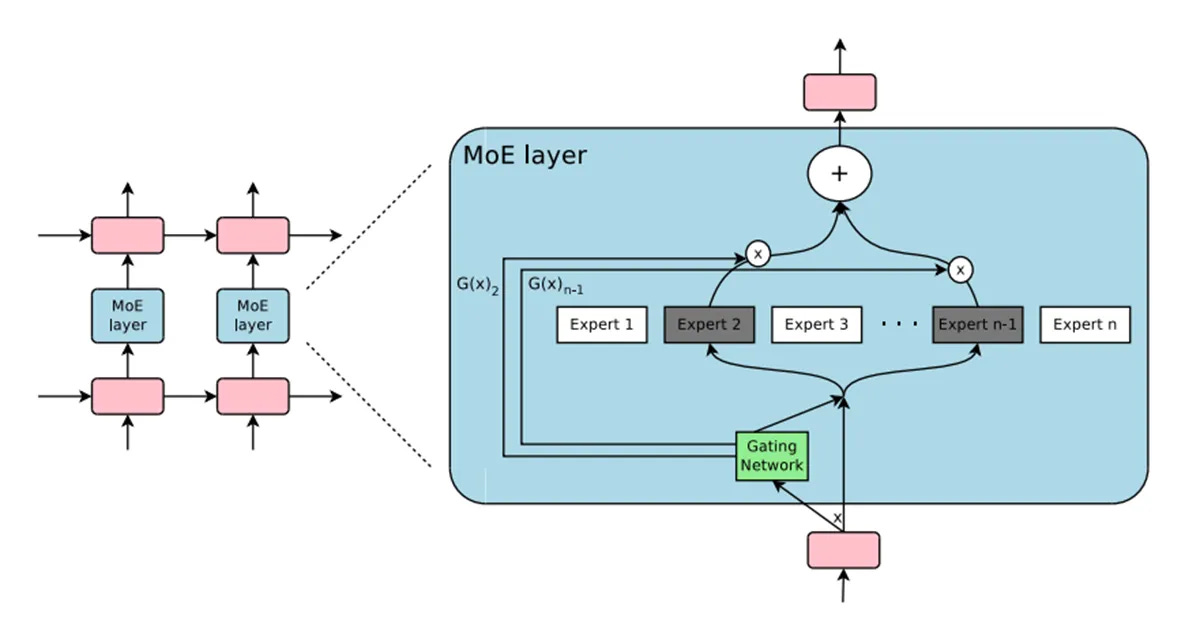
Training at Scale
The sheer scale of Qwen2.5-Max’s training process is another factor that sets it apart. According to reports, the model was pre-trained on over 20 trillion tokens —a staggering amount of data that dwarfs many of its competitors. This massive dataset provides the model with a broad foundation of knowledge, enabling it to understand context deeply and generalize effectively across different scenarios.
But pre-training is only part of the story. After the initial phase, Qwen2.5-Max underwent meticulous supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF). These steps ensure that the model doesn’t just spit out answers—it generates responses that align with human expectations and preferences. This level of refinement is crucial for creating AI systems that feel intuitive and reliable.
Benchmark Performance
When it comes to AI models, benchmarks are the ultimate proving ground—and Qwen2.5-Max doesn’t disappoint. In head-to-head comparisons, it has gone toe-to-toe with some of the biggest names in the game, including GPT-4o and Claude-3.5-Sonnet , and walked away with bragging rights. But what really stands out is how it crushes specific, high-stakes tests where precision and adaptability matter most.
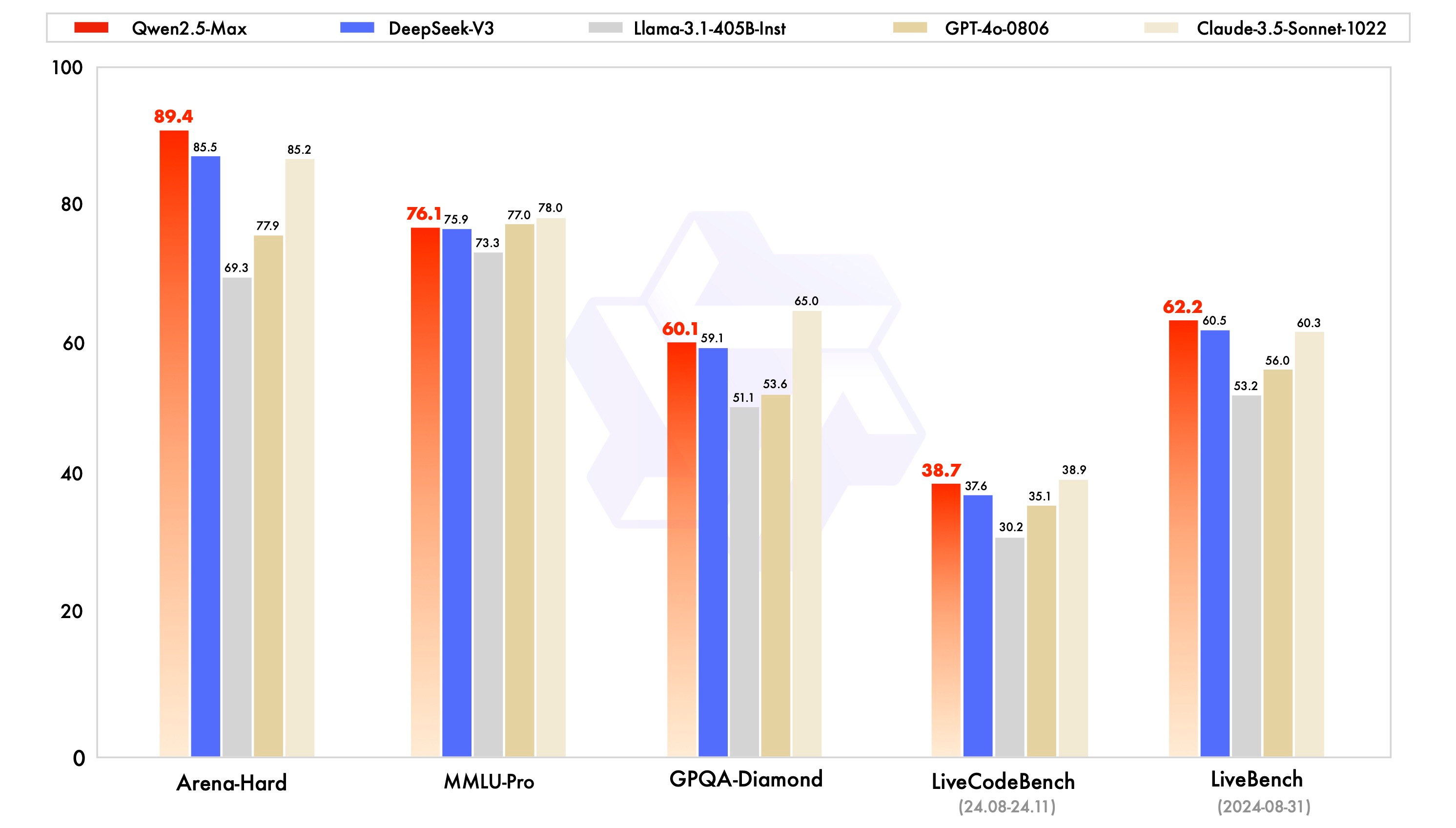
1. Arena-Hard: Reasoning Under Pressure
Take Arena-Hard , for example—a benchmark designed to push models to their limits with complex reasoning tasks. Think of it as the mental equivalent of running a marathon while solving puzzles. Qwen2.5-Max didn’t just survive; it thrived, showcasing its ability to handle intricate, multi-step challenges with ease. If you’re looking for an AI that can think on its feet, this one’s a winner.
2. LiveBench & LiveCodeBench: A Developer’s Best Friend
For developers, LiveBench and LiveCodeBench are where the rubber meets the road. These benchmarks simulate real-world coding and debugging scenarios, testing whether an AI can actually help you write cleaner, smarter code—or if it’s just good at talking about it. Spoiler alert: Qwen2.5-Max crushed it here too, proving itself as a reliable partner for everything from debugging to building scalable apps.
3. GPQA-Diamond: Smarter Answers, Better Insights
Then there’s GPQA-Diamond, which evaluates advanced question-answering abilities. This isn’t your average trivia night—it’s about providing nuanced, context-aware answers to tough questions. Qwen2.5-Max nailed it, delivering responses that were not only accurate but also intuitive and human-like. Whether you’re researching quantum physics or just trying to settle a debate about history, this model has your back.
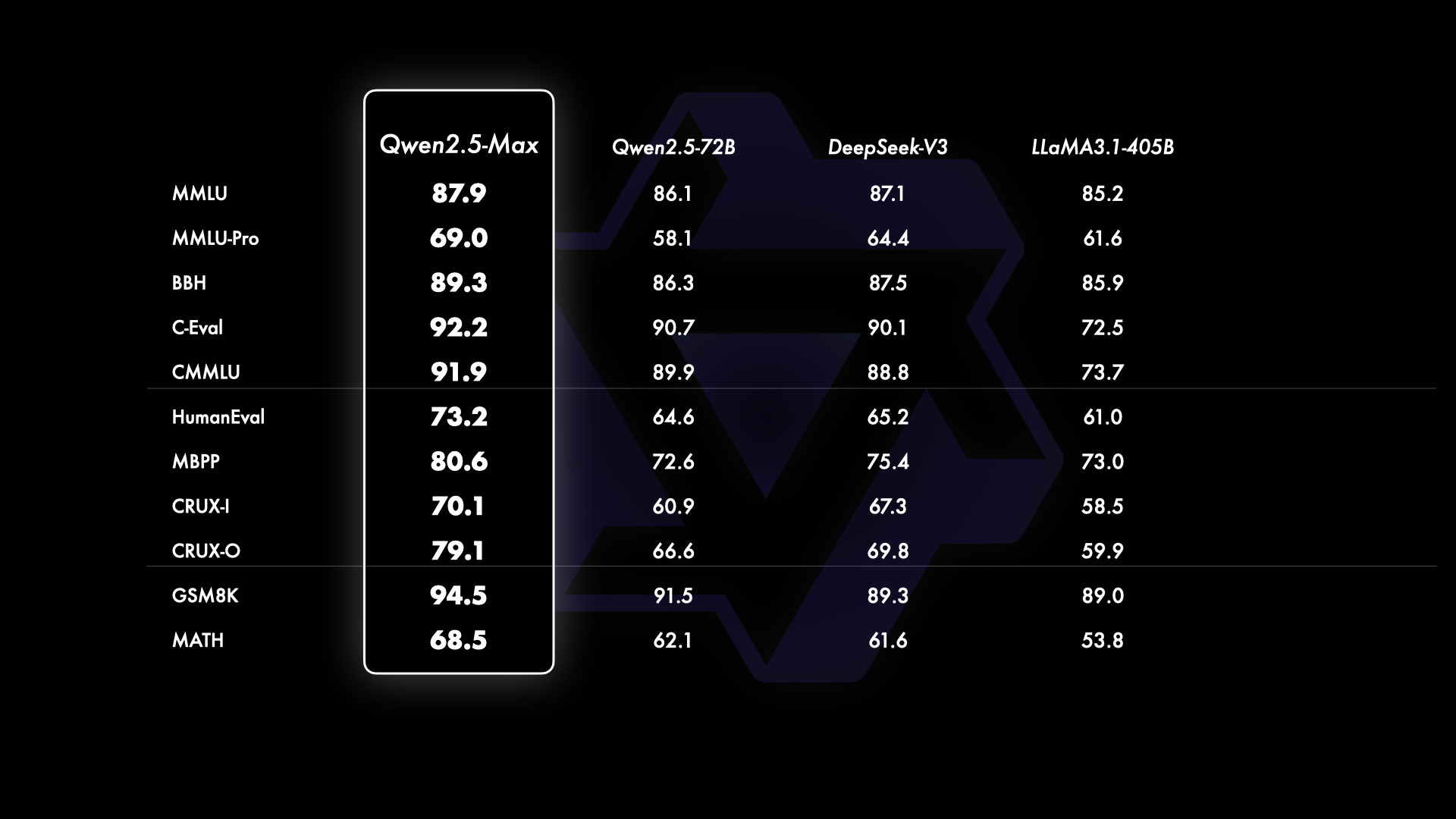
4. Base Model Comparisons: Outperforming the Competition
Even when stacked against other open-weight models like Llama-3.1-405B, Qwen2.5-Max holds its own. It outperformed many of its peers in foundational tests, proving that its base architecture is rock-solid. And let’s not forget—it even outpaced its smaller sibling, Qwen2, showing just how much Alibaba has leveled up.
5. Human Preference Alignment: The Secret Sauce
Finally, one of the most impressive aspects of Qwen2.5-Max is how well it aligns with human preferences. Thanks to meticulous reinforcement learning from human feedback (RLHF), the model doesn’t just spit out technically correct answers—it delivers responses that feel natural and relatable. It’s like having a conversation with someone who actually gets you.
These benchmarks aren’t just numbers—they’re proof that Qwen2.5-Max is built for real-world challenges. Whether it’s helping developers code faster, answering complex questions, or reasoning through tough problems, this model is ready to roll. It’s not perfect—no model is—but its combination of versatility, efficiency, and accessibility makes it a standout player in the AI landscape.
So, the next time someone asks why Qwen2.5-Max matters, you can tell them this: it’s not just another AI model. It’s a glimpse into what happens when innovation meets ambition—and trust me, the results are worth paying attention.
Implications for AI Research and Innovation
Beyond its raw capabilities, Qwen2.5-Max holds profound implications for the future of AI research and innovation. Here’s why:
1. Democratizing Access to Cutting-Edge AI
One of the most exciting aspects of Qwen2.5-Max is its open-source availability. By making the model accessible to developers, researchers, and enterprises worldwide, Alibaba is fostering a more inclusive and collaborative AI ecosystem. This move contrasts sharply with the proprietary models that often dominate the field, locking users into restrictive ecosystems. Open-source tools like Qwen2.5-Max empower smaller players—startups, academic institutions, and independent developers—to experiment, innovate, and build solutions tailored to niche problems. This democratization of AI could accelerate progress across industries, from healthcare to education to entertainment.
2. Challenging Traditional Power Structures
Historically, the AI landscape has been dominated by a handful of Western tech giants. However, models like Qwen2.5-Max and DeepSeek-V3 signal a shift in the balance of power. These advancements demonstrate that China is not just keeping pace with global leaders but actively contributing groundbreaking innovations. This geopolitical dynamic adds a fascinating layer to the ongoing AI arms race.
3. Paving the Way for Multimodal AI
Looking ahead, one area to watch closely is multimodal AI systems capable of processing and integrating multiple types of inputs, such as text, images, and audio. While Qwen2.5-Max currently focuses on language-based tasks, its underlying architecture lays the groundwork for future iterations that could handle multimodal challenges. Imagine an AI assistant that doesn’t just answer questions but also interprets visual data, generates creative content, and interacts with users in real-time. The possibilities are endless.
Challenges and Opportunities Ahead
Of course, no model is without its limitations. Critics have pointed out that Qwen2.5-Max may struggle against the latest reasoning-focused models, particularly in complex, multi-step tasks. Additionally, while its open-source nature is a strength, it also raises questions about quality control and ethical use. As AI becomes more accessible, ensuring responsible deployment will be paramount.
That said, these challenges are opportunities in disguise. Ongoing improvements in post-training methods, combined with community-driven innovation, could address many of these concerns. Future versions of Qwen are likely to push the boundaries even further, solidifying Alibaba’s position as a leader in AI development.
Final Thoughts
At its core, Qwen2.5-Max isn’t just another AI model—it’s a testament to how far we’ve come in our quest to replicate and augment human intelligence. Its combination of scalability, versatility, and accessibility positions it as a transformative force in the AI landscape. Whether you’re a researcher exploring the frontiers of machine learning, a developer building the next big app, or simply someone curious about the future of technology, Qwen2.5-Max offers a glimpse into what’s possible when innovation meets ambition.
As we continue to explore the potential of large-scale models like Qwen2.5-Max, one thing is clear: the journey is far from over. And if this model is any indication, the road ahead promises to be nothing short of extraordinary.